RLBench
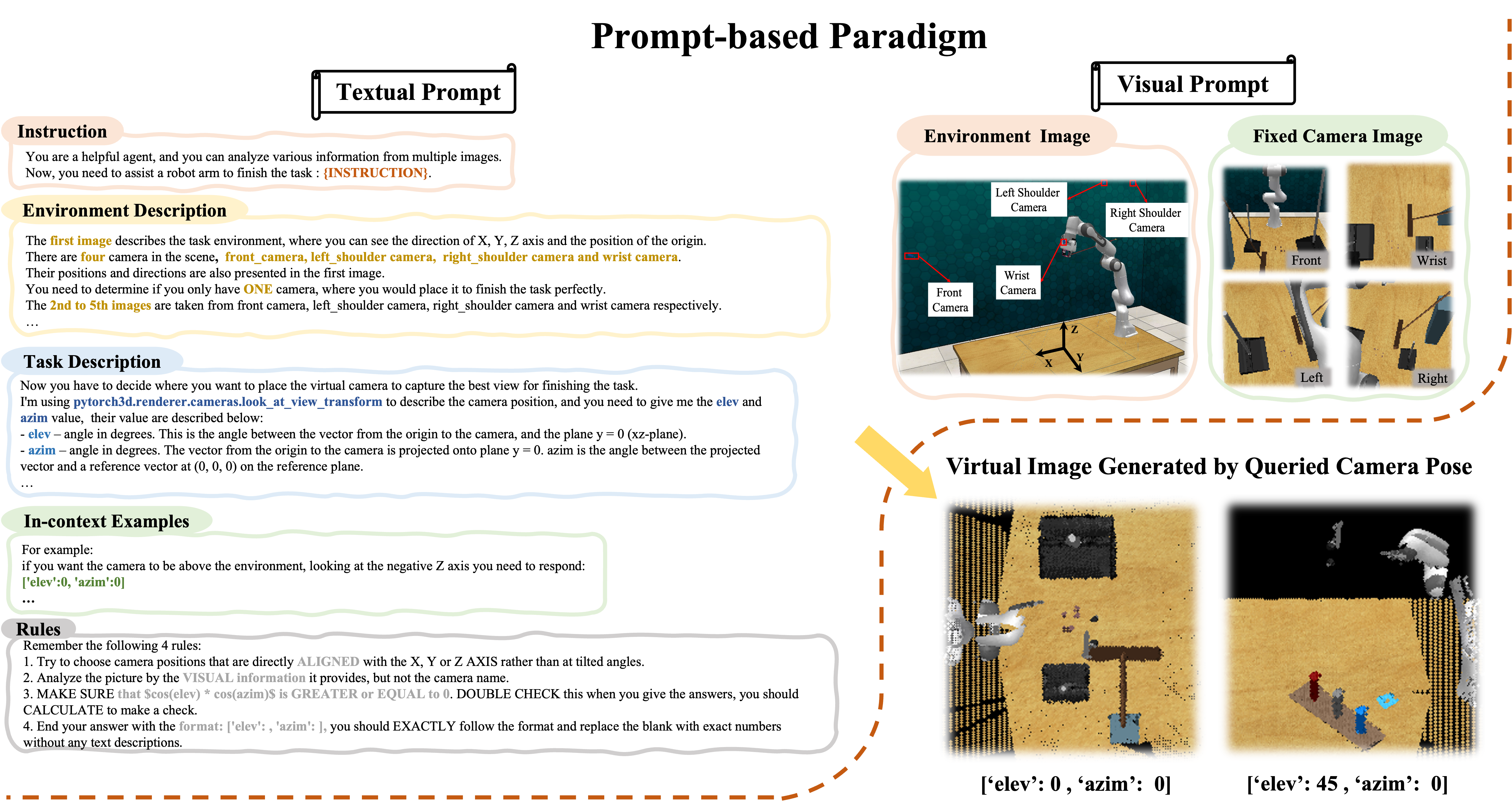
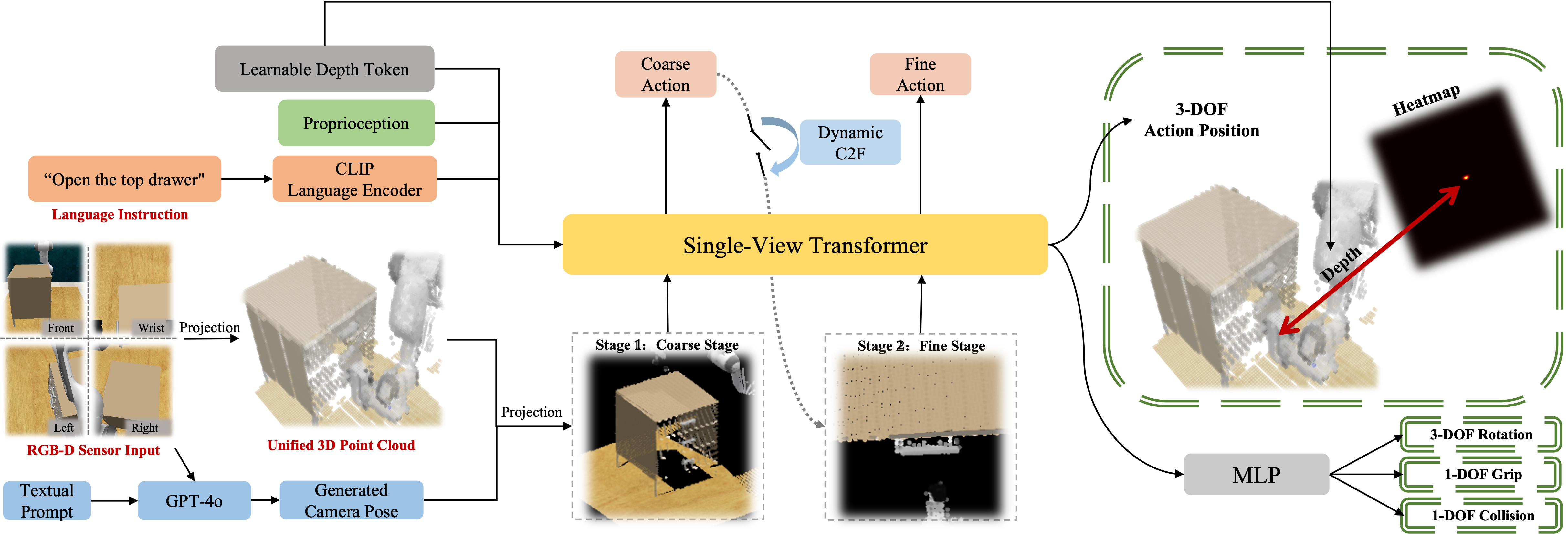
We evaluate VERM on the RLBench simulation benchmark. VERM achieves 1.89× speedup in training time and 1.54× speedup in inference speed compared to RVT-2 (see Figure 3), while surpassing it by 1.4% in average task success rate and performing best in 11 out of 17 tasks (see Table 1). We also test VERM with different foundation models (GPT-4o, Qwen2.5, and Claude 3.5 Sonnet) and achieve comparable performance across all models (see Table 2).
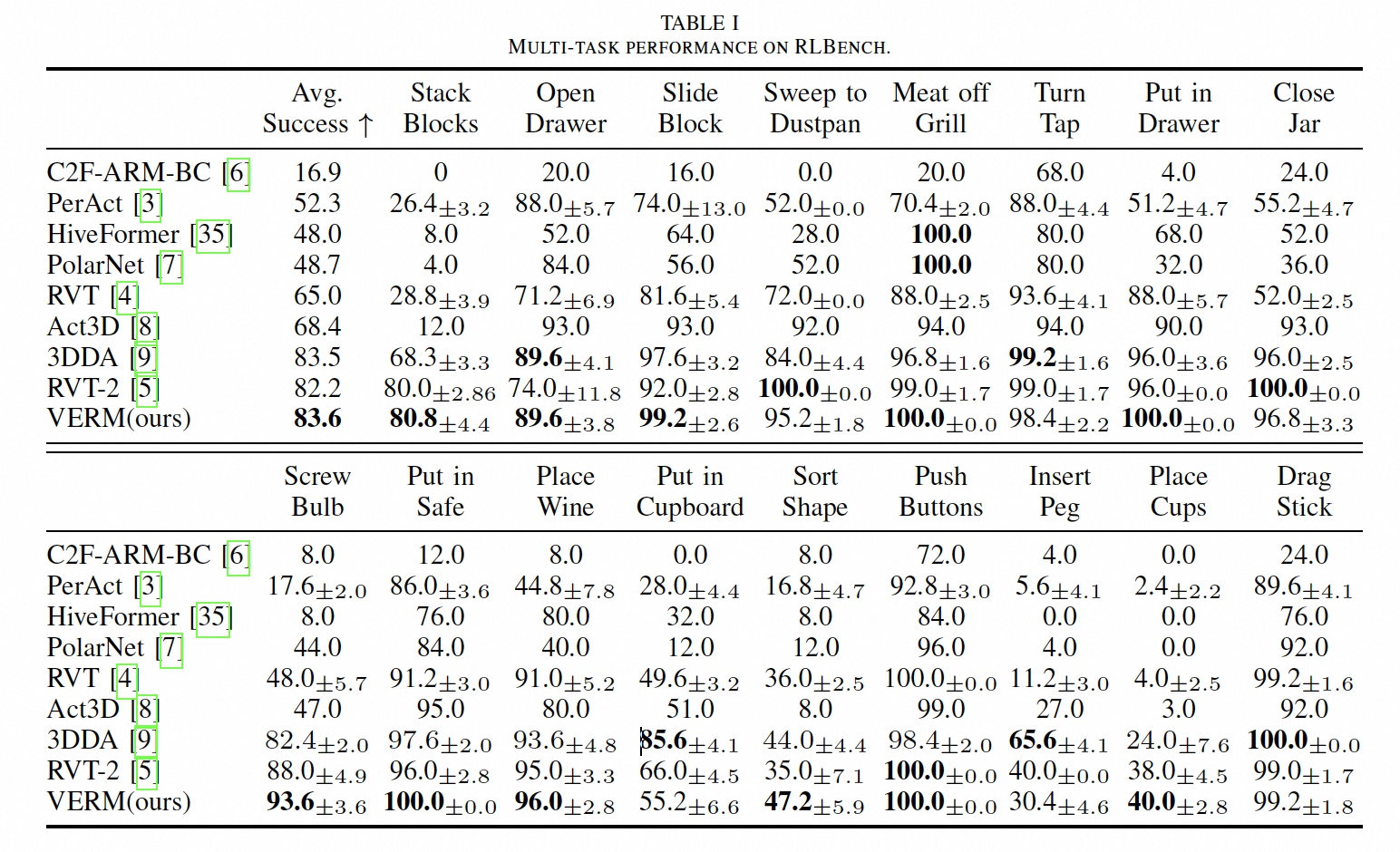
Table 1: Results on RLBench benchmark.

Figure 3:Training time (left) and inference speed (right) comparison.
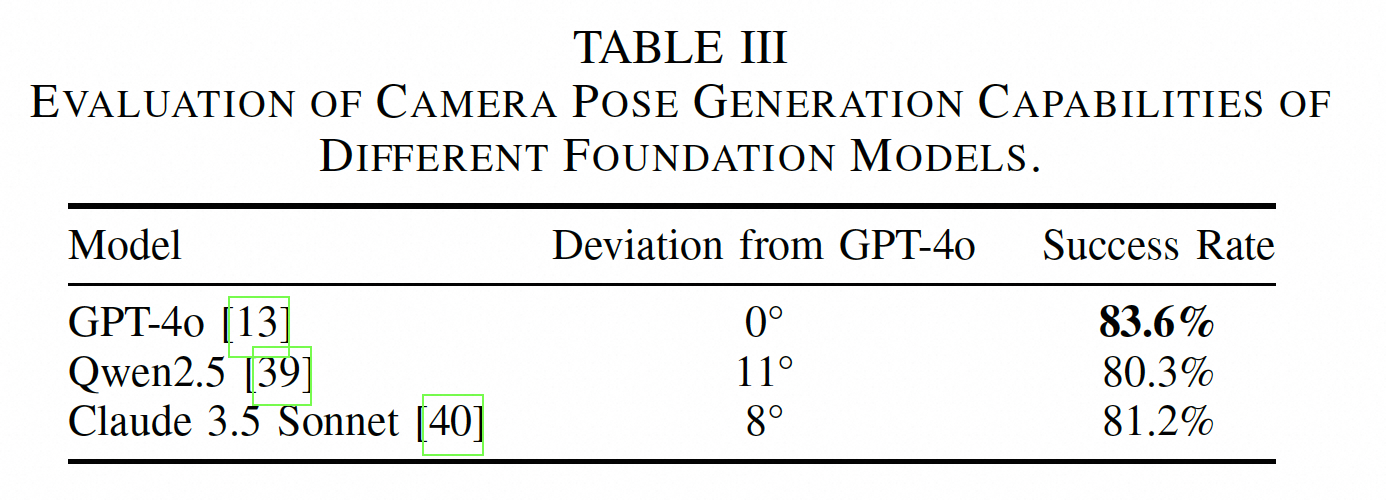
Table 2: Cross-model generalization results with different foundation models.
Real-World Evaluation
We evaluate VERM on eight real-world manipulation tasks. VERM achieves strong performance with just 15 demonstrations, already outperforming RVT and RVT-2 in most tasks while significantly reducing both training time and inference latency.
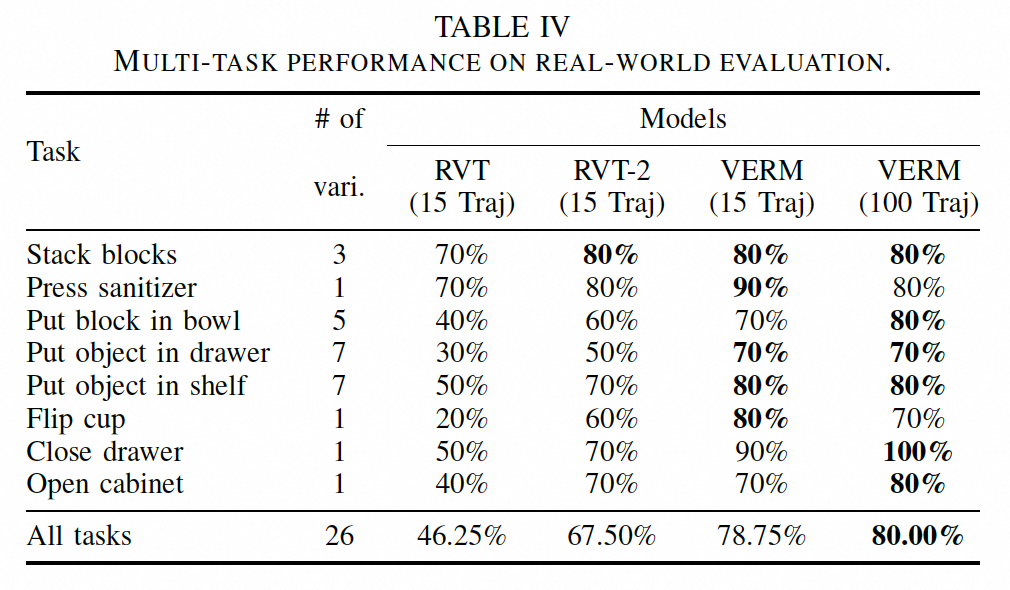
Table 3: Results on real-world manipulation tasks.
Real-World Task Demonstrations
Stack Blocks
Put in Drawer
Put in Shelf
Put in Bowl